Разработчик сделал коммит в пятницу в 16:00. В понедельник утром изменения уже в рабочей базе. Без ручной загрузки конфигурации, без звонков админу, без блокировки пользователей на 20 минут посреди рабочего дня. Изменения в BSL-коде — вообще без перезапуска: hot deploy подхватывает их на лету.
Это не фантазия и не рекламный буклет вендора. Это реально работающий пайплайн, который мы построили для розничной сети с несколькими десятками пользователей и ежедневными изменениями в конфигурации. В этом материале — архитектура, грабли, на которые мы наступили, и конкретные решения, которые позволили сократить простой при обновлении с 20 минут до 3–5.
Зачем CI/CD для 1С — бизнес-аргументы
В классической схеме обновление конфигурации 1С выглядит так: разработчик выгружает CF-файл, передаёт его администратору (по почте, через мессенджер, через сетевую папку), администратор ждёт окно обслуживания, выгоняет пользователей, загружает конфигурацию, обновляет базу данных, запускает пользователей обратно. Между коммитом и рабочей базой — от нескольких часов до нескольких дней ручной работы.
У этого подхода три фундаментальные проблемы:
- Человеческий фактор. Забыли передать файл, загрузили не ту версию, обновили не ту базу. Каждый ручной шаг — точка потенциального отказа.
- Простой пользователей. Полная загрузка конфигурации через Конфигуратор блокирует базу на 15–30 минут. Если делать это в рабочее время — менеджеры, бухгалтеры и кладовщики сидят без дела. Если ночью — кто-то должен не спать.
- Страх релиза. Чем сложнее и дольше процесс обновления, тем реже его делают. Накапливаются изменения, растёт риск, каждый релиз превращается в стрессовое событие. Разработчики копят исправления неделями, потом выкатывают всё разом — и если что-то сломалось, непонятно, какой из двадцати коммитов виноват.
CI/CD решает все три проблемы. Коммит в Git запускает автоматическую цепочку: проверка кода, сборка, тестирование, деплой. Человек делает одно действие — пушит код. Всё остальное происходит без его участия.
Для руководителя IT-отдела CI/CD — это контроль. Видно, кто что изменил, когда изменение попало в продуктив, какие проверки оно прошло. Для финансового директора — это экономия: меньше простоев, меньше часов администрирования, меньше авральных исправлений в выходные с оплатой по двойному тарифу. Для разработчика — это свобода: можно сосредоточиться на коде, а не на логистике файлов.
Бизнес-эффекты, которые мы зафиксировали на реальном проекте:
- Время от коммита до продуктива: с 1–2 дней до 40 минут (автоматически).
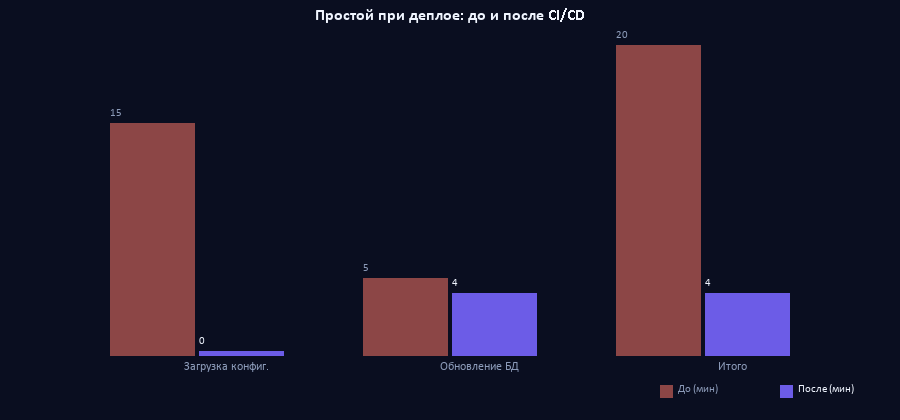
- Простой пользователей при обновлении: с 20–30 минут до 3–5 минут, а при hot deploy — 0 минут.
- Количество инцидентов при обновлении: снизилось втрое за первые три месяца.
- Частота релизов: с 1–2 раз в неделю до ежедневной доставки исправлений.
- Откат при проблемах: вместо «найди CF от прошлой пятницы в сетевой папке» — git revert и автоматический деплой предыдущей версии.

Архитектура пайплайна: восемь этапов от коммита до продуктива
Пайплайн построен на GitHub Actions с self-hosted runners. Раннеры — это машины внутри контура заказчика, на которых установлена платформа 1С, EDT и вспомогательные инструменты. GitHub Actions оркестрирует процесс, а вся тяжёлая работа происходит локально.
Стратегия ветвления: три ветки.
- feature/* — ветки разработки отдельных задач. Создаются от develop, вливаются обратно через pull request.
- develop — интеграционная ветка. Сюда попадают все принятые изменения. При пуше запускается деплой на тестовую базу.
- productive — ветка продуктива. Обновляется через merge из develop после успешного тестирования на dev-базе. При пуше — деплой на рабочую базу. Merge в productive — это осознанное решение о готовности к релизу, а не случайный пуш.
Восемь этапов пайплайна при пуше в develop или productive:
- BSL Lint. Статический анализ кода на соответствие стандартам 1С. Проверяет именование переменных, неиспользуемые переменные, пустые блоки, дублирование кода, использование устаревших методов платформы. Быстрый этап — занимает 1–2 минуты. Если lint не прошёл, пайплайн останавливается, разработчик получает уведомление с указанием конкретных строк и правил. Это первый рубеж защиты: в продуктив не попадёт код с очевидными проблемами.
- SonarQube. Глубокий анализ качества кода. Ищет потенциальные ошибки, уязвимости, code smells, дублирование кода между модулями. Результаты накапливаются от коммита к коммиту — видна динамика качества кода по проекту. Quality Gate блокирует merge, если новый код ухудшает метрики ниже установленного порога.
- Export из EDT. Конвертация исходников из формата EDT (src/) в XML через 1cedtcli. Это критически важный этап, о подводных камнях которого мы расскажем отдельно.
- Сборка CF. Загрузка XML в промежуточную базу через LoadConfigFromFiles и выгрузка CF-файла. Выполняется на dev-машине с self-hosted runner.
- Загрузка конфигурации на сервер. CF передаётся на целевой сервер и загружается через LoadCfg. Этот этап НЕ требует эксклюзивного режима — пользователи продолжают работать.
- Обновление базы данных (UpdateDBCfg). Собственно применение изменений к структуре базы данных. Здесь определяется стратегия: hot deploy или full deploy.
- Backup. Автоматическое резервное копирование базы перед критическими операциями с ротацией: хранятся копии за последние 7 дней.
- Уведомление. Результат деплоя отправляется в Telegram-канал команды: успех, предупреждение (hot deploy не прошёл, откат на full), ошибка. Сообщение содержит ссылку на коммит, имя автора, краткое описание изменений и время выполнения каждого этапа. При ошибке — лог последних 50 строк вывода, чтобы разработчик мог диагностировать проблему без захода в GitHub Actions.
Full deploy по расписанию запускается с понедельника по пятницу в 07:00, до начала рабочего дня. В это время пайплайн блокирует сессии через rac.exe, выполняет полное обновление и разблокирует базу. К 07:15–07:20 пользователи входят в уже обновлённую систему.
Почему именно GitHub Actions, а не Jenkins, GitLab CI или TeamCity? Три причины. Во-первых, заказчик уже хранил код в GitHub — не нужен дополнительный сервис. Во-вторых, self-hosted runners позволяют выполнять задачи на машинах внутри контура, где установлена платформа 1С, — не нужно передавать базы и конфигурации наружу. В-третьих, YAML-конфигурация workflow хранится в том же репозитории, что и код, — изменения в пайплайне проходят тот же процесс ревью через pull request.
Hot deploy: обновление без остановки пользователей
Hot deploy — механизм 1С, который позволяет обновить BSL-код (модули объектов, модули форм, общие модули) без перезапуска сеансов. Пользователи продолжают работать, а при следующем серверном вызове получают обновлённый код.
Ключевой параметр: /UpdateDBCfg -Dynamic+. Если изменения затрагивают только BSL — обновление происходит на лету. Если изменилась метаданные (добавлен реквизит, изменена структура регистра) — платформа возвращает код ошибки 2, и пайплайн автоматически откатывается на full deploy.

Логика в пайплайне выглядит так:
- Попробовать
UpdateDBCfg -Dynamic+. - Если exit code = 0 — успех, BSL обновлён без простоя.
- Если exit code = 2 — есть изменения метаданных, hot deploy невозможен. Откладываем до ближайшего окна full deploy (07:00).
- Если exit code ≠ 0 и ≠ 2 — ошибка, уведомление в Telegram, ручное разбирательство.
На практике около 60–70% коммитов в проекте розничной сети содержали только BSL-изменения и применялись через hot deploy мгновенно. Это означало, что исправление ошибки в отчёте или алгоритме расчёта попадало в продуктив в течение часа после коммита — без звонков, без блокировок, без административной волокиты.
Важный нюанс: hot deploy обновляет код на сервере, но клиентские сеансы получают новый код не мгновенно. Обновление происходит при следующем серверном вызове — когда пользователь нажимает кнопку, открывает форму или выполняет любое действие, требующее обращения к серверу. Для большинства сценариев это прозрачно. Но если изменение затрагивает критическую логику (например, расчёт скидок на кассе), стоит предупредить пользователей о необходимости перезайти — или дождаться окна full deploy.
Ещё одно ограничение: hot deploy работает только с серверным кодом. Изменения в клиентских модулях (код формы, выполняемый на клиенте) требуют переоткрытия формы пользователем. Это не полная перезагрузка и не блокировка базы, но об этом нужно помнить при планировании релизов.
Три уровня хирургии: минимизация простоя
Когда hot deploy невозможен и нужен полный UpdateDBCfg, встаёт вопрос: как минимизировать время, когда пользователи не могут работать?
Уровень 1: разделение загрузки и обновления
Ключевое наблюдение, которое меняет всю архитектуру деплоя: LoadConfigFromFiles (загрузка конфигурации из файлов) не требует эксклюзивного режима. Пользователи продолжают работать, пока конфигурация загружается в информационную базу. Это самый длительный этап — 10–15 минут для крупной конфигурации. И всё это время пользователи спокойно проводят документы, формируют отчёты, работают как обычно.
Блокировка нужна только на этапе UpdateDBCfg — применения изменений к структуре базы данных. А это уже 3–5 минут. Разница между «база недоступна 20 минут» и «база недоступна 4 минуты» — принципиальная для бизнеса. Четыре минуты можно провести за чашкой кофе. Двадцать — это потерянный час работы отдела из 15 человек.
Уровень 2: избирательное завершение сессий
Стандартный подход — заблокировать базу и выкинуть всех. Но у нас на сервере одновременно работают тонкие клиенты пользователей и сеансы Конфигуратора (от CI/CD). При загрузке конфигурации нужно завершить только сеансы Конфигуратора, а пользователей не трогать до последнего момента.
Решение: через rac session list получаем список сессий, фильтруем по app-id: Designer, завершаем только их командой rac session terminate. Тонкие клиенты продолжают работать. Блокировка пользователей — только непосредственно перед UpdateDBCfg, на минимально возможное время.
На практике это выглядит так: пайплайн запускает LoadConfigFromFiles, пользователи работают. Загрузка занимает 10–15 минут. Затем пайплайн через rac получает список сеансов, находит сеансы Designer от предыдущего этапа, завершает их. После этого устанавливает блокировку начала сеансов, завершает оставшиеся пользовательские сеансы, выполняет UpdateDBCfg (3–5 минут), снимает блокировку. Пользователи подключаются заново. Суммарный простой — те самые 3–5 минут вместо 20.
Уровень 3: deadlock и его разрешение
Отдельная история, стоившая нам двух дней отладки. Для автоматической блокировки и разблокировки базы мы использовали HTTP-сервис самой базы 1С. Логика казалась элегантной: у HTTP-сервиса есть аутентификация, токен, код простой — вызвал эндпоинт, база заблокирована.
Проблема проявилась при разблокировке. Цепочка событий:
- Пайплайн вызывает HTTP-сервис — база блокируется.
- Регламентные задания останавливаются (база же заблокирована).
- Обновление завершается.
- Пайплайн вызывает HTTP-сервис для разблокировки.
- Запрос зависает. Навсегда.
Причина: HTTP-сервис живёт в том же процессе, что и платформенный планировщик. Когда база заблокирована, фоновые задания не запускаются. HTTP-запрос на разблокировку — это тоже серверный вызов, который ставится в очередь и ждёт разблокировки. Классический deadlock: чтобы разблокировать базу, нужно выполнить запрос; чтобы выполнить запрос, нужно разблокировать базу.
Решение: отказаться от HTTP-сервиса для управления блокировками. Вместо этого — rac.exe, утилита администрирования кластера 1С. Она обращается к кластеру напрямую через порт RAS (по умолчанию 1545), минуя прикладной уровень 1С. Rac не зависит от состояния базы, регламентных заданий и блокировок — работает всегда.
Урок, который мы вынесли: никогда не используйте для управления жизненным циклом базы инструменты, которые сами живут внутри этой базы. HTTP-сервис, внешняя обработка через COM — всё это зависит от состояния процесса rphost. Rac работает на уровне кластера, через отдельный процесс ras, и является единственным надёжным способом управлять блокировками и сеансами из внешних скриптов.
Грабли, которые мы нашли за вас
Грабля 1: EDT, XML и пропадающий BSL
Пайплайн: EDT (src/) → экспорт в XML → LoadConfigFromFiles → UpdateDBCfg -Dynamic+. Всё логично, всё работает. Кроме одного: BSL-изменения не применяются. Hot deploy отрабатывает успешно, но код в базе остаётся старым.
Два дня, четыре варианта скриптов, более десяти итераций. Проблема оказалась в способе экспорта из EDT.
Стандартный путь экспорта EDT → XML шёл «через базу»: EDT выгружает конфигурацию в промежуточную базу 1С, а затем из этой базы формирует XML. Промежуточная база «съедала» BSL-изменения: она сравнивала текст модулей со своей версией и не включала их в итоговый XML, если считала, что они совпадают. Самое коварное в этой ситуации — отсутствие ошибок. Пайплайн отрабатывал зелёным, hot deploy возвращал код 0, но фактически ни одна строка BSL не менялась в рабочей базе. Обнаружить это можно было только ручной проверкой кода через Конфигуратор.
Рабочий путь: использовать 1cedtcli export --configuration-files. Эта команда берёт BSL напрямую из проекта EDT, без промежуточной базы. Файлы модулей попадают в XML как есть, и hot deploy корректно их подхватывает.
Совет: если вы строите пайплайн с hot deploy, проверяйте именно BSL-изменения на каждом этапе конвейера. Простой тест — изменить одну строку в общем модуле, запустить пайплайн и убедиться через Конфигуратор, что изменение дошло до рабочей базы. Этот тест стоит делать при любых изменениях в скриптах экспорта и сборки — слишком легко сломать цепочку и не заметить.
Грабля 2: concurrency groups и заблокированный продуктив
GitHub Actions позволяет задавать concurrency groups, чтобы два деплоя не запускались одновременно. Мы задали группу по имени раннера: логично, один раннер — один деплой в момент времени.
Проблема: dev и prod использовали одну и ту же группу раннеров. Деплой на dev-базу (который занимает 15–20 минут) блокировал раннер, и деплой на prod вставал в очередь. Разработчик пушит в develop, начинается деплой на тест — и внезапно продуктив не может обновиться в своё окно 07:00, потому что раннер занят.
Решение: разделить concurrency groups по окружению. Отдельная группа для develop, отдельная для productive. В YAML это одна строка: concurrency: deploy-${{ github.ref_name }} вместо concurrency: deploy. А ещё лучше — выделить отдельные раннеры для каждого контура, чтобы они не конкурировали за ресурсы физически. Если бюджет не позволяет второй сервер, как минимум разнесите concurrency groups — это бесплатно и решает 90% проблем с очередями.
Грабля 3: кэширование и состояние раннера
Self-hosted runner — это не эфемерный контейнер. Он сохраняет состояние между запусками. Если предыдущий деплой завершился аварийно и оставил залоченные файлы, открытые COM-соединения или запущенные процессы 1С, следующий запуск может упасть по совершенно неочевидной причине.
Мы добавили в начало каждого workflow шаг cleanup: принудительное завершение процессов 1cv8.exe и 1cv8c.exe, очистка временных каталогов, проверка доступности портов RAS и ragent. Без этого шага примерно один из десяти запусков падал из-за «зависших» процессов от предыдущей сборки. После добавления cleanup за три месяца не было ни одного ложного падения по этой причине.
Отдельная рекомендация: мониторьте свободное место на диске раннера. Промежуточные базы, XML-выгрузки, CF-файлы и бэкапы быстро накапливаются. Мы настроили автоматическую очистку артефактов старше 3 дней — это ещё один шаг в начале workflow, который занимает секунды, но предотвращает неожиданные падения из-за переполнения диска.
Итог
CI/CD для 1С — это не про моду на DevOps и не про слепое копирование практик из веб-разработки. Это про предсказуемость. Когда каждый коммит проходит одну и ту же цепочку проверок и деплоя, команда перестаёт бояться релизов. Обновления становятся рутиной, а не событием.
Восемь этапов пайплайна, hot deploy для BSL, избирательное завершение сессий, rac.exe вместо HTTP-сервиса — это конкретные инструменты, проверенные на рабочем проекте розничной сети. Каждый из них решает конкретную проблему и экономит конкретное время.
Если у вас команда из двух и более разработчиков 1С, версионирование кода в Git, и обновления чаще раза в неделю — CI/CD окупится в первый же месяц. Не количеством строк автоматизации, а отсутствием ночных звонков и утренних разборов «кто загрузил не ту версию».
Начать можно с малого: автоматический lint при pull request и деплой на тестовую базу при merge в develop. Два этапа, один workflow-файл, один self-hosted runner. Когда команда привыкнет к автоматическим проверкам и увидит первые результаты — добавить hot deploy, SonarQube, деплой на продуктив. Пайплайн растёт вместе с проектом, а каждый новый этап решает конкретную боль, которую команда уже почувствовала на себе.